|
|
在现实生活中,很多人的资料是不愿意公布在互联网上的,但是我们又要使用人工智能的能力帮我们处理文件、做决策、执行命令那怎么办呢?于是我们构建自己或公司的私人GPT变得非常重要。
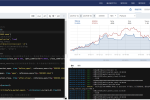
先看效果:



一、本地部署PrivateGPT
快速本地安装步骤:
1. 克隆存储库:
git clone https://github.com/imartinez/privateGPT

文件目录

2. 安装 Python :
pyenv install 3.11.0b4

pyenv local 3.11.0b4
(如果报错可以直接安装python3.11)
系统之前已经安装过3.10的旧版本,为了避免干扰需要从系统变量path中删除:C:\Program Files\Python310\Scripts\;C:\Program Files\Python310\
3. 安装依赖:
poetry install --with ui,local

4. 下载嵌入和 LLM 模型:
poetry run python scripts/setup



5. (可选,在powershell中运行)启用GPU:
$env:CMAKE_ARGS='-DLLAMA_CUBLAS=on'; poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python

6. 运行本地服务器:
set PGPT_PROFILES=local
poetry run python -m private_gpt

7. 导航到 UI:在浏览器中打开 http://localhost:8001/。

参考1:
●Git 是一个免费和开源 的分布式版本控制系统,旨在以速度和效率处理从小型到大型项目的所有内容.Git易于学习 占用空间小,性能快如闪电. 它优于 SCM 工具,如 Subversion, CVS, Perforce, 和 ClearCase 具有 廉价的本地分支, 方便的 暂存区域, 和 多个工作流等功能.下载Git
●PowerShell 是微软发布的一种命令行外壳程序和脚本环境,使命令行用户和脚本编写者可以利用 .NET Framework的强大功能修改PowerShell的执行策略,PowerShell的执行策略不允许运行脚本,修改策略的方法是以管理员方式运行PowerShell,执行如下命令
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned
恢复默认策略
Set-ExecutionPolicy -ExecutionPolicy Restricted
●pip则是python第三方库的包管理工具。需要在Python的官网上去>>下载<<
下载完成之后解压运行,输入:
python setup.py install
安装好之后,我们直接在命令行输入pip,同样会显示‘pip’不是内部命令,也不是可运行的程序。因为我们还没有添加环境变量,在path中添加pip的路径。通常是:
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Scripts
列出已安装的软件包:python -m pip list
安装软件包:python -m pip install SomePackage
卸载安装包:python -m pip uninstall SomePackage
●pyenv是一个简单的python版本管理工具。它可以让你轻松地在多个版本的 Python 之间切换。ython每当从此文件夹中调用时,都会使用给定的版本。这与虚拟环境不同,虚拟环境需要显式激活。它简单、不引人注目,并且遵循 UNIX 单一用途工具只做好一件事的传统
pip install pyenv-win --target $home\\.pyenv --no-user --upgrade

添加系统设置
[System.Environment]::SetEnvironmentVariable('PYENV',$env:USERPROFILE + "\.pyenv\pyenv-win\","User")
[System.Environment]::SetEnvironmentVariable('PYENV_ROOT',$env:USERPROFILE + "\.pyenv\pyenv-win\","User")
[System.Environment]::SetEnvironmentVariable('PYENV_HOME',$env:USERPROFILE + "\.pyenv\pyenv-win\","User")
[System.Environment]::SetEnvironmentVariable('path', $env:USERPROFILE + "\.pyenv\pyenv-win\bin;" + $env:USERPROFILE + "\.pyenv\pyenv-win\shims;" + [System.Environment]::GetEnvironmentVariable('path', "User"),"User")

更多pyenv资料
检查安装情况,查看版本和支持安装python的版本:
pyenv --version
pyenv install -l | findstr 3.11
使用 pip 安装(卸载)任何库或修改版本文件夹中的文件后,必须运行pyenv rehash以使用 Python 和库的可执行文件的新填充程序更新 pyenv。
注意:这必须在文件夹外部运行.pyenv。
要卸载 python 版本:pyenv uninstall 3.5.2
要查看您正在使用哪个 python 及其路径:pyenv version
要查看该系统上安装的所有 python 版本:pyenv versions
●Poetry 是 Python 中的依赖管理和打包工具。它允许您声明您的项目所依赖的库,并且它将为您管理(安装/更新)它们。Poetry 提供了一个锁定文件来确保可重复安装,并可以构建您的项目以进行分发。需要Python 3.8+。
安装指令:
(Invoke-WebRequest -Uri https://install.python-poetry.org -UseBasicParsing).Content | py -

Invoke-WebRequest是PowerShell中类似curl的模块,从网页中获取内容。
●Chocolatey是windows下的软件包管理工具,使用chocolatey可以快速的安装软件,输如choco install softname即可。
●安装依赖llama-cpp-python的问题
For Windows 10/11
To install a C++ compiler on Windows 10/11, follow these steps:
Install Visual Studio 2022.
Make sure the following components are selected:
Universal Windows Platform development
C++ CMake tools for Windows
Download the MinGW installer from the MinGW website.
Run the installer and select the gcc component.
MinGW:GNU 编译器集合 (GCC) 的本机 Windows 端口,具有可免费分发的导入库和头文件,用于构建本机 Windows 应用程序;包括对 MSVC 运行时的扩展以支持 C99 功能。MinGW 的所有软件都将在 64 位 Windows 平台上执行。

代码中加上force_download=True和resume_download=False参数,强制重新下载模型文件并禁用断点续传
EMBEDDINGS_MODEL_NAME:SentenceTransformers词向量模型位置,可以指定HuggingFace上的路径(会自动下载)
分析本地文件
privateGPT支持以下常规文档格式分析,例如(仅列举了最常用的):
Word文件:.doc,.docx
PPT文件:.ppt,.pptx
PDF文件:.pdf
纯文本文件:.txt
CSV文件:.csv
Markdown文件:.md
电子邮件文件:.eml,.msg
将需要分析的文档(不限于单个文档)放到privateGPT根节点下的source_documents目录下
运行ingest命令对文档进行分析
python ingest.py
Creating new vectorstore
Loading documents from source_documents
Loading new documents: 100%|██████████████████████| 1/1 [00:01<00:00, 1.42s/it]
Loaded 1 new documents from source_documents
Split into 7 chunks of text (max. 500 tokens each)
Creating embeddings. May take some minutes...
Using embedded DuckDB with persistence: data will be stored in: db
Ingestion complete! You can now run privateGPT.py to query your documents
注意:如果db目录中已经有相关分析文件,则会对数据文件进行积累。如果只想针对当前文档进行解析,请清空db目录后再ingest。
启用GPU,
安装
安装CPP

启动
BLAS

GPU使用

默认的 pip 安装行为是llama.cpp仅在 Linux 和 Windows 上针对 CPU 进行构建,并在 MacOS 上使用 Metal。llama.cpp支持多种硬件加速后端,包括 OpenBLAS、cuBLAS、CLBlast、HIPBLAS 和 Metal。所有这些后端都受支持llama-cpp-python,并且可以通过CMAKE_ARGS在安装之前设置环境变量来启用。CMAKE_ARGS在 Windows 上你可以这样设置:
●cmake 是 c/c++ 的一个项目管理工具。远古人类使用 make, 后来慢慢用 automake/autoconf/libtool 这些工具。 后来有人重新轮了几个,包括 scon, gyp , cmake。
cmake 一开始是 kde 的项目的管理工具,后来越来越多的人使用了。CMAKE_ARGS 指明在子项目中运行 cmake 时,cmake 的命令行参数。
1:
$env:CMAKE_ARGS='-DLLAMA_CUBLAS=on'; poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python
2:
$env:CMAKE_ARGS = "-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS";pip install llama-cpp-python
通过运行nvcc-version和nvidia-smi验证您的安装是否正确,确保您的CUDA版本是最新的,并检测到您的GPU。
高级配置
增加线程数以提升速度
privateGPT.py实际是调用了llama-cpp-python的接口,因此如果不做任何代码修改则采用的默认解码策略。打开privateGPT.py查找以下语句(大约30-35行左右,根据不同版本有所不同)。
llm = LlamaCpp(model_path=model_path, n_ctx=model_n_ctx, callbacks=callbacks, verbose=False)
这里即是LlamaCpp模型的定义,可根据llama-cpp-python的接口定义传入更多自定义参数,以下是其中一个示例,额外增加了解码线程数量,有助于提升解码速度(请根据实际物理核心数酌情配置)。
llm = LlamaCpp(model_path=model_path, n_ctx=model_n_ctx, callbacks=callbacks, verbose=False, n_threads=8)
在上述定义后几行会使用LangChain的RetrievalQA进行交互,具体定义和配置方式请参考LangChain的文档
有时候CMD出现错误提示,是因为CMD的权限不够

参考2:
https://www.bilibili.com/video/BV1zN411M7Fn?t=8.4
从0到1训练自己的大模型 揭密ChatGPT背后的技能与应用「核心原理」
GPT Chat接入详解
如何把数据接入GPT
privateGPT官方帮助文档
|
|



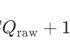






























 楼主
楼主