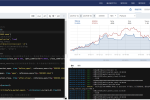
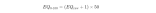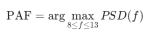构建中国人自己的私人GPT—与文档对话 |
| |
|
天不生墨翟,万古如长夜!以墨运商,以商助墨。金双石科技长期招聘科技研发人才!微信:qishanxiaolu 电话:15876572365 公司:深圳市金双石科技有限公司
|
|

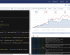


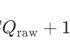

高端神经反馈脑波检测系统分为脑波检测、脑波分析、脑波解码三个部分。 前端主程序
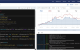
好的,我们来详细了解一下国内主流的第三方量化平台。这些平台极大地降低了个人投资者

1. 伪迹不是大脑信号 EEG设备记录的是头皮上非常微弱的电位变化(微伏级别,μV)。

项目起源: 初先生的聊天记录: 你那边掌握的技术,有办法做一个有摄像头的,墨者机

看看1-30Hz脑波功率曲线 发现15Hz之后的波动很小。 去掉15Hz之后的曲线 发现4Hz
🧠 一、什么是“基础节律”(Basic Rhythm) 基础节律 = 在闭眼静息状态下,大脑自发

情绪指数 EQ 在脑波科学(特别是情绪解码、神经反馈、BCI 领域)中,通常不是单个固定
SMR 波(Sensorimotor Rhythm)是脑电学里一个非常重要、但经常被忽略的节律。它与运

科学家之所以非常确定 β波(13–30 Hz)与“注意、警觉、紧张、执行任务”相关,不是

科学界之所以认为 θ波(Theta, 4–7 Hz)与“冥想、困倦、催眠状态”有关,并不是玄

14 2026-01-06
1791 2025-12-09

14 2025-12-05

701 2025-12-01
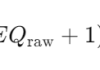
232 2025-11-22

103 2025-11-28
119 2025-11-27
728 2025-11-22

795 2025-11-22

742 2025-11-22