gbk' codec can't decode byte 0xad in |
| |
|
天不生墨翟,万古如长夜!以墨运商,以商助墨。金双石科技长期招聘科技研发人才!微信:qishanxiaolu 电话:15876572365 公司:深圳市金双石科技有限公司
|
|
| |
|
天不生墨翟,万古如长夜!以墨运商,以商助墨。金双石科技长期招聘科技研发人才!微信:qishanxiaolu 电话:15876572365 公司:深圳市金双石科技有限公司
|
|
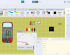

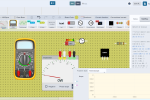
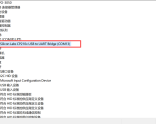
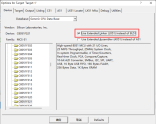
Windows的设备管理器中可以查看USB设备的信息: 驱动程序供应商:FTDI, 数字签名者:
https://velxio.dev/ Arduino、ESP32 和 Raspberry Pi。 直接在您的浏览器中即可使
你的ESP32开发板被电脑识别为“CP2102”,这并不是一个错误,而是完全正常的现象。这
做固件加密,本质上是防止别人读取或复制你的程序。常见做法分为“芯片级保护 + 软件

高端神经反馈脑波检测系统分为脑波检测、脑波分析、脑波解码三个部分。 前端主程序
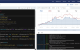
好的,我们来详细了解一下国内主流的第三方量化平台。这些平台极大地降低了个人投资者

1. 伪迹不是大脑信号 EEG设备记录的是头皮上非常微弱的电位变化(微伏级别,μV)。

项目起源: 初先生的聊天记录: 你那边掌握的技术,有办法做一个有摄像头的,墨者机

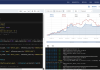
看看1-30Hz脑波功率曲线 发现15Hz之后的波动很小。 去掉15Hz之后的曲线 发现4Hz
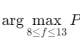
🧠 一、什么是“基础节律”(Basic Rhythm) 基础节律 = 在闭眼静息状态下,大脑自发
869 2026-05-23
973 2026-05-19
1178 2026-05-09
1536 2026-04-06

16 2026-01-06
3487 2025-12-09

24 2025-12-05

1974 2025-12-01
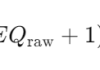
234 2025-11-22

106 2025-11-28








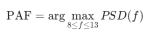









 楼主
楼主