|
|
unsloth 微调
微调的定义
大模型微调是利用特定领域的数据集对已预训练的大模型进行进一步训练的过程。它旨在优化模型在特定任务上的性能,使模型能够更好地适应和完成特定领域的任务。
unsloth简介
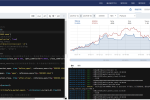
unsloth微调Llama 3, Mistral和Gemma速度快2-5倍,内存减少80% !unsloth是一个开源项目,它可以比HuggingFace快2-5倍地微调Llama 3、Mistral和Gemma语言模型,同时内存消耗减少80%。
#本机训练最大的好处就是数据安全有保障。无论是个人 企业 还是机构,数据都是最宝贵的产之一,传到云端无论怎么加密都会承担泄露风险,而用本机训练模型则安全经济便捷。
#使用网络数据集微调Llama3.1大模型
from unsloth import FastLanguageModel
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
max_seq_length = 2048 # Supports RoPE Scaling interally, so choose any!
# Get LAION dataset
url = "https://huggingface.co/datasets/laion/OIG/resolve/main/unified_chip2.jsonl"
dataset = load_dataset("json", data_files = {"train" : url}, split = "train")
# local_file = "/home/larry/Downloads/my_file.json";
# dataset = load_dataset("json", data_files = {"train" : local_file}, split = "train")
# dataset = dataset.map(formatting_prompts_func, batched = True,)
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b
"unsloth/llama-3-8b-bnb-4bit", # [NEW] 15 Trillion token Llama-3
"unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
max_seq_length = max_seq_length,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
tokenizer = tokenizer,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 60,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
seed = 3407,
),
)
trainer.train()
# model.save_pretrained("my_model") # save
# Go to https://github.com/unslothai/unsloth/wiki for advanced tips like
# (1) Saving to GGUF / merging to 16bit for vLLM
# (2) Continued training from a saved LoRA adapter
# (3) Adding an evaluation loop / OOMs
# (4) Cutomized chat templates
使用本地数据集来微调Llama3.1大模型
from unsloth import FastLanguageModel
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
max_seq_length = 2048 # Supports RoPE Scaling interally, so choose any!
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/gemma-7b-bnb-4bit",
"unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b
"unsloth/gemma-2b-bnb-4bit",
"unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b
"unsloth/llama-3-8b-bnb-4bit", # [NEW] 15 Trillion token Llama-3
"unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
max_seq_length = max_seq_length,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
# Get local dataset
local_file = "/home/larry/Downloads/my_file.json";
dataset = load_dataset("json", data_files = {"train" : local_file}, split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
tokenizer = tokenizer,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 60,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
seed = 3407,
),
)
trainer.train()
model.save_pretrained("my_model") # save
# Go to https://github.com/unslothai/unsloth/wiki for advanced tips like
# (1) Saving to GGUF / merging to 16bit for vLLM
# (2) Continued training from a saved LoRA adapter
# (3) Adding an evaluation loop / OOMs
# (4) Cutomized chat templates
测试微调过的Llama3.1大模型
from unsloth import FastLanguageModel
from transformers import TextStreamer
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "my_model", # the model that you trained
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
alpaca_prompt = """Based on given instruction and context, generate an appropriate response.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
alpaca_prompt.format(
"小林最擅长的什么领域的工作?", # instruction
"", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
inputs = tokenizer(
[
alpaca_prompt.format(
"小林AI实验室的好评率是多少", # instruction
"", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
inputs = tokenizer(
[
alpaca_prompt.format(
"小林在Youtube开频道的初衷是什么?", # instruction
"", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
本地数据集
[{
"instruction": "金双石科技是一家什么样的公司?",
"input": "",
"output": "金双石科技是一家继承墨家思想的科技公司"
}, {
"instruction": "刘世奇最擅长的什么领域的工作?",
"input": "",
"output": "刘世奇擅长软件研发和视频制作,AI大模型的微调"
}, {
"instruction": "刘世奇抖音节目的风格是什么?",
"input": "",
"output": "用简单的语言和方法讲解一个复杂的AI主题"
}, {
"instruction": "刘世奇在Youtube开频道的初衷是什么?",
"input": "",
"output": "充分体验学习的充实和分享的快乐"
}, {
"instruction": "刘世奇AI实验室的宗旨是什么?",
"input": "",
"output": "分享最新最好AI工具的使用方法"
}]

参考:https://studywithlarry.com/unsloth-llama-3/
重要参考:https://blog.csdn.net/asd54090/article/details/140669032
|
|



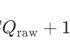






























 楼主
楼主