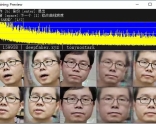
视频和音频合成视频Easy_Wav2Lip |
| |




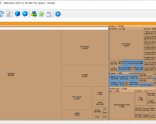
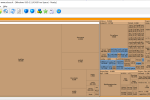
有时候硬盘很满了,又不知道是哪个程序占用了太多大的空间。 就可以用SpaceSniffer

这里有VR 各种AI软件 绘图 炼丹 地址:

上一期给大家讲了什么是数字人,今天给大家讲入手一个3D数字人要多少钱? 数字人包括
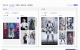
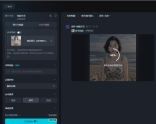
本质上是一种视频换脸技术的升级版,视频换身。 项目体验地址: https://www.modelsco

他可以根据一段视频生成3D环境模型,他能根据视频角度去完善模型,对模型进行AI补全,

Meta推出的Llama 3.1系列包括80亿、700亿、4050亿参数版本,上下文长度扩展至12.8万to
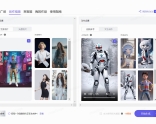
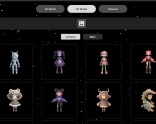
清华大学创作的AI软件 aiuni Aiuni.ai是一个基于Unique3D的在线AI图片转3D模型生成建

阿里的免费声音克隆工具CosyVoice CosyVoice 是阿里通义实验室在七月初开源的一款专

一、知毛泽东,不知有墨子。 二、知墨子,但依然儒法道行事。 三、知墨子,尝试墨家
https://hyperhuman.deemos.com/ 上传图片,点击生成 可以多生成几次,点击应用
0 2024-09-16

4180 2024-06-20

172 2024-09-11

175 2024-09-11

607 2024-07-30
1749 2024-03-17
222 2024-09-08
173 2024-09-08

238 2024-09-08
238 2024-09-07