|
|
语音驱动口型的算法
先看效果:
FACEGOOD 决定将语音驱动口型的算法技术正式开源,这是 AI 虚拟数字人的核心算法,技术开源后将大程度降低 AI 数字人的开发门槛。FACEGOOD是一家国际领先的3D基础软件开发商,研究领域涉及生物软组织模拟、运动科学、计算机图形学等,其核心产品软件AVATARY广泛应用于国内外影视动画、游戏、虚拟人应用场景的娱乐、文化、媒体等行业的3D数字内容制作,提供优秀的数字工程设计、娱乐软件服务和媒体娱乐行业和基础设施行业的产品和技术解决方案。 2022年6月28日,FACEGOOD(量子动力(深圳)计算机科技有限公司)作为国内首批企业以Principle Member身份正式加入Metaverse Standard Forum(元宇宙标准论坛)。
下载工程
git clone https://github.com/FACEGOOD/FACEGOOD-Audio2Face.git
文件如下:
文件

部署依赖
pip install PyAudio
pip install tensorflow
pip install websocket ,websocket-client
pyaudio库,使用这个可以进行录音,播放,生成wav文件等等。PyAudio 提供了 PortAudio 的 Python 语言版本,这是一个跨平台的音频 I/O 库,使用 PyAudio 你可以在 Python 程序中播放和录制音频。为PoTaTudio提供Python绑定,跨平台音频I/O库。使用PyAudio,您可以轻松地使用Python在各种平台上播放和录制音频.
PyAudio更多
相关版本如下:tersorflow-gpu 2.6
cudatoolkit 11.3.1 cudnn 8.2.1 scipy 1.7.1
python-libs:pyaudio 请求 websocket websocket-client
申请智能语音API接口
会话精灵(Talking Genie) “ www.talkinggenie.com ”,是思必驰新近推出的针对企业智能服务的定制平台,提供虚拟机器人的在线定制服务。
会话精灵为客户提供通过API接入的方式,获取智能会话、语音识别、语音合成等服务的能力。如果您自主开发前端应用,可以通过创建API接入类型的产品,对接会话精灵的相关能力。
请前往会话精灵文档中的以下地址: https: //login.tgenie.cn/,申请一个产品帐号来替换您项目中的产品帐号。选择 "智能语音API接入",获取到PID、PublicKey、SecretKey。

修改配置文件
将获取到的KEY填入到配置文件:zsmeif_aispeech_config.json 对应的参数中
productId:会话精灵ID
PublicKey是应用标识,在开放api调用过程中唯一标识一个应用;
SecretKey是调用API时的Token,用来验证请求的合法性
Token:Token api接口生成的token,必须和productId是对应的关系
配置

接口: /aispeech/portal/api/v1/ba
同时支持语音识别、对话和语音合成功能
上述3个功能可同时使用
◑对query.type 传入 url 或者voice时,即表示使用语音识别功能。
一句话识别就是对一分钟内的短语音进行识别,适用于对话聊天,控制口令等较短的语音识别场景。
支持音频编码格式:pcm(无压缩的pcm文件或wav文件)、ogg\wav 8000\16000; mp3\flv 16000\22050\44100; amr 8000的单声道(mono)。
仅支持单声道
支持音频采样率:8000Hz、16000Hz。
支持对返回结果进行设置:处理唤醒词,是否识别结果需要加标点符号,是否将中文数字转为阿拉伯数字输出(逆文本)。支持多种语言的识别,资源模型选择
接口地址:https://api.talkinggenie.com/aispeech/portal/api/v1/ba/asr
◑传入dialog.enableDialog = true 时,即表示使用对话功能
会话接口地址:https://api.tgenie.cn/api/v1/ba
◑对output.type传入tts或者url时,即表示使用语音合成功能,语音合成提供将输入文本合成为语音二进制数据流或者音频下载url的功能
参数中的asr, tts, audio如果不传入,即表示使用默认参数,如果不符,会影响服务的使用
接口地址:https://api.tgenie.cn/api/v1/tts
实时语音识别,对于实时采集到的录音流传输做识别,适用于麦克风实时采集数据,边接收边识别的不间断识别的场景。
/aispeech/runtime/v3/recognize?productId=914005898&token=a616baa5-c203-4b0f-8cd0-1cd7418d734d
下载FaceGoodLiveLink
FaceGoodLiveLink.exe程序请从这里下载:data_all code : n6ty
启动
python zsmeif.py
run

当终端显示“run main”消息时,请运行位于/example/ueExample/文件夹中的FaceGoodLiveLink.exe

在UE项目的屏幕上点击并按住鼠标左键,即可与AI模型对话并等待语音和动画响应。

错误处理
1:ERROR: Handshake status 429 Too Many Requests -+-+- {'server': 'nginx/1.15.3', 'date': 'Mon, 04 Mar 2024 03:08:29 GMT', 'content-type': 'application/json; charset=UTF-8', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', 'cache-control': 'no-store, no-cache, must-revalidate, max-age=0', 'x-content-type-options': 'nosniff', 'x-frame-options': 'DENY', 'x-xss-protection': '1 ; mode=block'} -+-+- None
ERROR: Could not create connection: ws://api.tgenie.cn/runtime/v3/recognize?res=comm&productId=914020983&token=114d40a6-ad9d-408e-b47a-16d9c9fe1a9d
429

在 HTTP 协议中,响应状态码 429 Too Many Requests 表示在一定的时间内用户发送了太多的请求,即超出了“频次限制”。
去会话精灵中申请一个产品帐号
2:Error Main loop: Expecting value: line 1 column 1 (char 0)

在会话精灵中选择 "智能语音API接入"。
这两个问题都是配置文件里的参数没有设置好。注意是一句话识别,传入的语音数据时长不能超过60s。
音频产生表情的流程
常规的神经网络模型训练大致可以分为三个阶段:数据采集制作、数据预处理和数据模型训练。
第一阶段,数据采集制作。这里主要包含两种数据,分别是声音数据和声音对应的动画数据。声音数据主要是录制中文字母表的发音,以及一些特殊的爆破音,包含尽可能多中发音的文本。而动画数据就是,在 maya 中导入录制的声音数据后,根据自己的绑定做出符合模型面部特征的对应发音的动画;
第二阶段,主要是通过 LPC 对声音数据做处理,将声音数据分割成与动画对应的帧数据,及 maya 动画帧数据的导出。
第三阶段就是将处理之后的数据作为神经网络的输入,然后进行训练直到 loss 函数收敛即可。
项目地址:https://github.com/FACEGOOD/Audio2Face 更多:机器之心
在Unity中应用可以用过构建python服务,Unity客户端开启麦克风录制音频,将音频数据发送给python服务端,服务端转换为驱动BlendShape的权重数据后,返回给Unity客户端进行驱动。需要注意的是Unity中BlendShape的权重范围并不是[-1,1],因此需要进行映射。

参考:
国内首批!FACEGOOD以主要成员正式加入Metaverse Standard Forum 出处:bilibili 作者:FACEGOOD官方
近实时智能应答 2D 数字人搭建 作者:薛东 AWS 解决方案架构师,负责基于 AWS 云平台的解决方案咨询和设计
别再狂吹数字人了 作者:商隐社
30天揽金5千万,AI数字人能成为普通人的「财富密码」?
有道数字人形象定制
METAHUMAN轻松制作高保真数字人类
Facegood面捕全流程:AVATARY操作方法
Unity & FACEGOOD Audio2Face 通过音频驱动面部BlendShape
实时智能应答数字人搭建 |
|





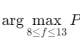



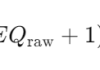








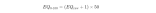

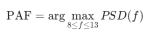









 楼主
楼主