|
|
GPT3模型实际是在3w张A100卡上训练的。如果成本底点,在1000张A100卡上训练一次需要2个月,购买GPU和配套+机房托管+电费成本至少也要1-2亿。
语料准备
要想训练出一个好的模型,需要喂入优质的语料,以下是从网上收集到的部分语料数据集。
1、THUCNews
清华大学自然语言处理与社会人文计算实验室THUCNews中文文本数据集
https://thunlp.oss-cn-qingdao.aliyuncs.com/THUCNews.zip
2、维基百科
https://pan.baidu.com/s/1uPMlIY3vhusdnhAge318TA
json版(wiki2019zh),104万个词条(1,043,224条; 原始文件大小1.6G,压缩文件519M;数据更新时间:2019.2.7),可以做为通用中文语料,做预训练的语料或构建词向量,也可以用于构建知识问答。
3、新闻语料
https://drive.google.com/file/d/ ... Kp/view?usp=sharing
json版(news2016zh),包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文( 原始数据9G,压缩文件3.6G;新闻内容跨度:2014-2016年)。训练集:243万;验证集:7.7万。
可以做为【通用中文语料】,训练【词向量】或做为【预训练】的语料; 也可以用于训练【标题生成】模型,或训练【关键词生成】模型(选关键词内容不同于标题的数据); 亦可以通过新闻渠道区分出新闻的类型。
4、百科类问答
https://pan.baidu.com/s/12TCEwC_Q3He65HtPKN17cA # fu45
json版(baike2018qa),含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。训练集:142.5万;验证集:4.5万。
可以做为通用中文语料,训练词向量或做为预训练的语料;也可以用于构建百科类问答;其中类别信息比较有用,可以用于做监督训练,从而构建 更好句子表示的模型、句子相似性任务等。
5、社区问答
https://drive.google.com/open?id ... AK6Bzc5XrngHstQTf0v
json版(webtext2019zh) 大规模高质量数据集,含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。从1400万个原始问答中,筛选出至少获得3个点赞以上的的答案,代表了回复的内容比较不错或有趣,从而获得高质量的数据集。除了对每个问题对应一个话题、问题的描述、一个或多个回复外,每个回复还带有点赞数、回复ID、回复者的标签。训练集:412万;验证集:6.8万;测试集:6.8万。可用于:
1)构建百科类问答:输入一个问题,构建检索系统得到一个回复或生产一个回复;或根据相关关键词从,社区问答库中筛选出你相关的领域数据
2)训练话题预测模型:输入一个问题(和或描述),预测属于话题。
3)训练社区问答(cQA)系统:针对一问多答的场景,输入一个问题,找到最相关的问题,在这个基础上基于不同答案回复的质量、 问题与答案的相关性,找到最好的答案。
4)做为通用中文语料,做大模型预训练的语料或训练词向量。其中类别信息也比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。
5)结合点赞数量这一额外信息,预测回复的受欢迎程度或训练答案评分系统。
6、翻译语料
https://drive.google.com/open?id ... hBO8Fh4e2j3b9C2bTVQ
translation2019zh中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。对于一个平行的中英文对,中文平均有36个字,英文平均有19个单词(单词如“she”)。训练集:516万;验证集:3.9万。
可以用于训练中英文翻译系统,从中文翻译到英文,或从英文翻译到中文; 由于有上百万的中文句子,可以只抽取中文的句子,做为通用中文语料,训练词向量或做为预训练的语料。英文任务也可以类似操作。
无论数据类型或目标如何,用于训练和使用 AutoML 模型的工作流都是相同的:
准备训练数据。
我们需要将需要训练的数据准备为jsonl格式,这种格式的特点就是每一行都是json的格式
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "医药和消费有什么基金推荐的", "completion": "医药可以看看工银前沿的赵蓓,她挺均衡的,对于这个行业我了解不多,你还可以看看医药100指数,消费挺多的,消费50也挺好。"}
{"prompt": "请教一下老师,恒生科技第一大持仓股是快手。而快手是亏损最大的互联网企业。似乎齐老师也说过不看好快手,会不会影响恒生科技持仓。", "completion": "如果你要是能选股,确实不应该买指数。从指数选择的角度来说。中概互联我们更看好一些。但他跟恒生科技的相关度其实很高"}
{"prompt": "想问一下国投瑞银这边基金公司和綦缚鹏的风格实力怎么样", "completion": "他风格不是很固定。最近在偏向周期。(个人观点,不作为投资建议)"}
其中,prompt是问题,completion是答案。
创建数据集。
openai tools fine_tunes.prepare_data -f dataset.jsonl
该指令会帮我们优化训练数据,该指令运行过程中会问我们几个问题,主要是给prompt添加了固定的后缀,比如”->”,给completion添加了开头的空格和结尾的换行符,如下
{"prompt":"医药和消费有什么基金推荐的 ->","completion":" 医药可以看看工银前沿的赵蓓,她挺均衡的,对于这个行业我了解不多,你还可以看看医药100指数,消费挺多的,消费50也挺好。\n"}
{"prompt":"请教一下老师,恒生科技第一大持仓股是快手。而快手是亏损最大的互联网企业。似乎齐老师也说过不看好快手,会不会影响恒生科技持仓。 ->","completion":" 如果你要是能选股,确实不应该买指数。从指数选择的角度来说。中概互联我们更看好一些。但他跟恒生科技的相关度其实很高\n"}
{"prompt":"想问一下国投瑞银这边基金公司和綦缚鹏的风格实力怎么样 ->","completion":" 他风格不是很固定。最近在偏向周期。(个人观点,不作为投资建议)\n"}
准备好的数据文件是dataset_prepared.jsonl
通常,tokenizer 有 2 种常用形式:WordPiece 和 BPE。
WordPiece
WordPiece 很好理解,就是将所有的「常用字」和「常用词」都存到词表中
WordPiece 的方式很有效,但当字词数目过于庞大时这个方式就有点难以实现了。
对于一些多语言模型来讲,要想穷举所有语言中的常用词(穷举不全会造成 OOV),
既费人力又费词表大小,为此,人们引入另一种方法:BBPE。
BPE 不是按照中文字词为最小单位,而是按照 unicode 编码 作为最小粒度。
对于中文来讲,一个汉字是由 3 个 unicode 编码组成的,
训练模型。
如果是微调,则是提交数据集
openai api fine_tunes.create -t dataset_prepared.jsonl -m curie
训练的进度可以通过下面这个命令获取,ft-SSIJ4DsHFfp9LEtuHWyQcn5B这个是fine-tuning的job ID,是上面create命令会给出的。
openai api fine_tunes.follow -i ft-SSIJ4DsHFfp9LEtuHWyQcn5B
用新模型进行提问
(.venv) ➜ openai api completions.create -m "curie:ft-personal-2023-04-04-15-28-34" -p "医药和消费有什么基金推荐的 ->"
Dify 是一个可视化、可运营、可改进的 LLM 训练平台,它提供了强大的 LLMOps 能力。此外,它还提供了搭建 Web App 的能力。这些意味着你可以用它快速开发一个专属于你的 ChatGPT 应用,你可以基于此进行训练、微调,直到它变成你喜欢的模样!
自己训练大模型
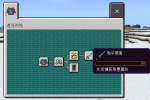
git clone https://github.com/xinzhanguo/hellollm.git
clone文件

下载成功之后文件
文件

cd hellollm
# 编译镜像(此处需要科学上网)
docker build -t hellollm:beta .
创建docker

# 可以选择以GPU方式运行
# docker run -it --gpus all hellollm:beta sh
docker run -it hellollm:beta sh
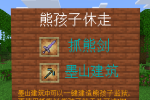
python sanguo.py
开始训练

GPU满负荷运转
GPU98

训练
训练2

训练完成,输出测试结果

评估和迭代模型。
从模型获取预测结果。
解读预测结果。
◆.gitignore 文件是一个纯文本文件,包含了项目中所有指定的文件和文件夹的列表,这些文件和文件夹是 Git 应该忽略和不追踪的。详情
◆Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。详情
◆requirements.txt 文件,里面内容是项目的依赖包及其对应版本号的信息列表,即项目依赖关系清单,其作用是用来重新构建项目所需要的运行环境依赖,比如你从 GitHub 上 clone 了一个 Python 项目,通常你会先找到 requirements.txt 文件,然后运行命令
pip install -r requirements.txt
来安装该项目所依赖的包。
同样,你也可以在你的项目目录下运行命令
pip freeze > requirements.txt
来生成 requirements.txt 文件,以便他人重新安装项目所依赖的包。详情
Vmmem 进程是系统合成的一个虚拟进程,用于表示虚拟机消耗的内存和 CPU 资源。如果您看到 Vmmem 消耗大量内存和 CPU 资源,那么这意味着您的虚拟机正在消耗大量内存和 CPU 资源。如果要让它停止,请关闭您的虚拟机。命令:
wsl –shutdown
微调:
ChatGPT进阶:利用Fine-tuning训练自己的模型
怎么训练自己的ai小模型?
手把手带你从0开始训练自己的yolov3模型(草履虫都能学会)
训练自己的目标检测模型(SSD篇)
仅用61行代码,你也能从零训练大模型 原创作者|辛占国
huggingface transformers使用指南之二——方便的trainer 作者 马东什么 算法工程师
如何训练一个自己的GPT模型 作者:闫金钢
【LLM】从零开始训练大模型 何枝 北京字节跳动科技有限公司 |
|

































 楼主
楼主